We are starting to wrap up the loose ends of LIDP 2. You will have seen some bonus blogs from us today, and we have more about reading lists and focus groups to come – plus more surprises!
Here is something we said we would do from the outset – a second version of the toolkit to reflect the work we have done in Phase 2 and to build on the Phase 1 Toolkit:
Stone, Graham and Collins, Ellen (2012) Library Impact Data Project Toolkit: Phase 2. Manual. University of Huddersfield, Huddersfield.
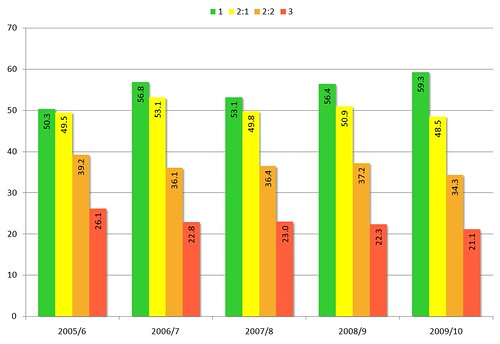
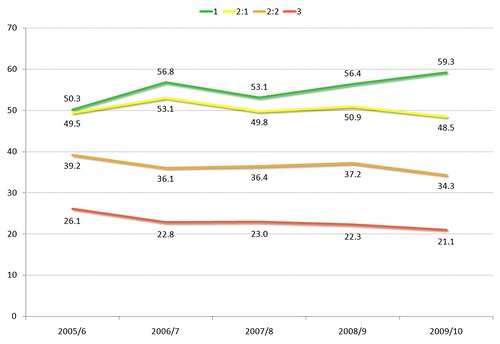
The second phase of the Library Impact Data Project set out to explore a number of relationships between undergraduate library usage, attainment and demographic factors. There were six main work packages:
- Demographic factors and library usage: testing to see whether there is a relationship between demographic variables (gender, ethnicity, disability, discipline etc.) and all measures of library usage;
- Retention vs non-retention: testing to see whether there is a relationship between patterns of library usage and retention;
- Value added: using UCAS entry data and library usage data to establish whether use of library services has improved outcomes for students;
- VLE usage and outcome: testing to see whether there is a relationship between VLE usage and outcome (subject to data availability);
- MyReading and Lemon Tree: planning tests to see whether participation in these social media library services had a relationship with library usage;
- Predicting final grade: using demographic and library usage data to try and build a model for predicting a student’s final grade.
This toolkit explains how we reached our conclusions in work packages 1, 2 and 6 (the conclusions themselves are outlined on the project blog. Our aim is to help other universities replicate our findings. Data were not available for work package 4, but should this data become available it can be tested in the same way as in the first phase of the project, or in the same way as the correlations outlined below. Work package 6 was also a challenge in terms of data, and we made some progress but not enough to present full results.
The toolkit aims to give general guidelines about:
1. Data Requirements
2. Legal Issues
3. Analysis of the Data
4. Focus Groups
5. Suggestions for Further Analysis
6. Release of the Data